之前以为Python逆向中的pyc就是简单的拿pycdc、uncompyle或者其他在线网站反编译,但是最近做了一些高质量的题目,就发现有pyc的题目经常跟Python的marshal模块一起出现,第一次遇到的时候还让我有点懵,而且也让我发现对pyc文件的认识还不太够,写这篇文章加深对pyc文件的理解,然后认识一下Python的marshal模块。
marshal
marshal — Internal Python object serialization — Python 3.8.19 documentation
链接是marshal模块的官方介绍。
该模块包含可以以二进制格式读取和写入Python值的函数。而在官方文档当中,我们会看到这样一句话

marshal模块的存在主要是为了支持阅读和编写.pyc文件的Python模块的“伪编译”代码。这也就不难理解为啥pyc文件总和marshal模块一起出现了。原来专门是为pyc而生的。官方文档解释的marshal模块的作用其实还是不好理解,我上网查阅了一下,发现该模块就是用来对对象进行序列化和反序列化的。
什么是序列化?之前Web方向好像有这个东西,网上搜也大多是啥Java序列化,后面我的理解就是序列化就是把一个数据对象转换成字节序列,也就是字节串,这样似乎就是方便传输数据,反序列化就是一个还原的过程。而该模块支持序列化的对象也在官方介绍中有提及

这里的code objects是我们特别需要关注的,他也是将pyc反序列化之后得到的数据类型。
marshal模块提供了四个函数。
#marshal.dumps()
import marshal
data = marshal.dumps(obj)这个函数可以把一个数据对象转换成字节串,下面是实例
import marshal
obj = {'Arnold': 'rightback', 'Number': 66, 2025: 'champion'}
data = marshal.dumps(obj)
print(data)
#输出b'\xfb\xda\x06Arnold\xda\trightback\xda\x06Number\xe9B\x00\x00\x00\xe9\xe9\x07\x00\x00\xda\x08champion0'这是一个序列化的过程,还有一个序列化的函数如下
#marshal.dump()
import marshal
with open('filename', 'wb') as f:
marshal.dump(obj, f)这个函数是先将一个数据对象转换成字节串之后,写入一个文件当中,文件必须是可写的二进制文件,所以我们打开文件的时候以wb的模式打开。
import marshal
obj = {'Arnold': 'rightback', 'Number': 66, 2025: 'champion'}
with open('bin.txt', 'wb') as f:
marshal.dump(obj, f)比如以上代码执行后,我们就可以在文件中看到写入了序列化后的数据。
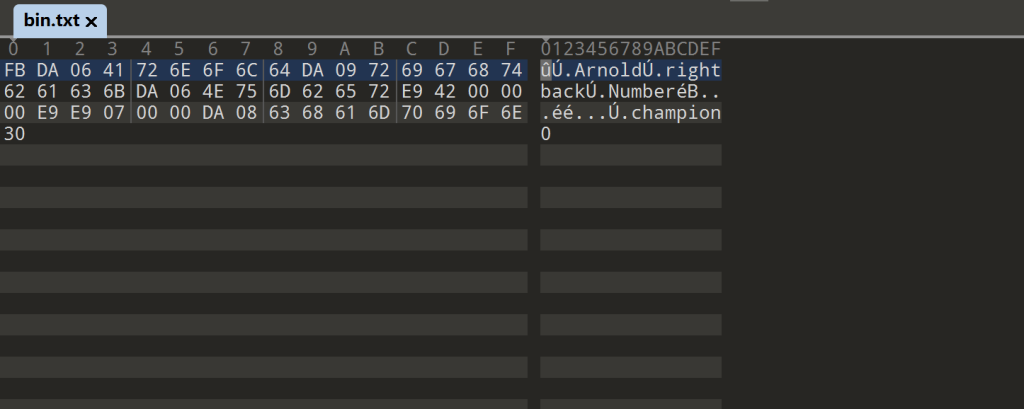
剩下来的两个就是相对应的,反序列化,还原出数据对象的函数
#marshal.load()
import marshal
with open('filename', 'rb') as f:
obj = marshal.load(f)该函数用于从文件中读取序列化的数据,并反序列化还原回数据对象,它只接收一个参数,就是文件。实例如下
import marshal
with open('bin.txt', 'rb') as f:
obj=marshal.load(f)
print(obj)
#输出{'Arnold': 'rightback', 'Number': 66, 2025: 'champion'}然后是第二个反序列化的函数
#marshal.loads()
import marshal
obj = marshal.loads(data)实例如下
import marshal
data=b'\xfb\xda\x06Arnold\xda\trightback\xda\x06Number\xe9B\x00\x00\x00\xe9\xe9\x07\x00\x00\xda\x08champion0'
obj=marshal.loads(data)
print(obj)
#输出{'Arnold': 'rightback', 'Number': 66, 2025: 'champion'}
当然marshal模块能够序列化的数据对象不止有字典,还有其他,只是拿来做个例子。
还有一点需要注意的就是,如果序列化之后,使用不同版本的Python是无法反序列化的。
pyc
.py文件在执行的时候代码会被编译成字节码,关于具体的Python程序执行的过程应该挺复杂的,在这里不做太多探讨。字节码是被包含在PyCodeObject对象中的,而.pyc文件里面就存放有该代码对象。我们先来看看如何生成pyc文件
import py_compile
py_compile.compile("ss.py")用以上代码就能生成一个_pycache_文件,里面放的就是pyc,这里我用python3.11生成的pyc无法用pycdc反编译,会报错Bad Magic! 但是在线网站可以反编译。所以我换了python3.8就可以了,这可能也是为什么Python逆向中的题目一般都不会是Python最新的版本。
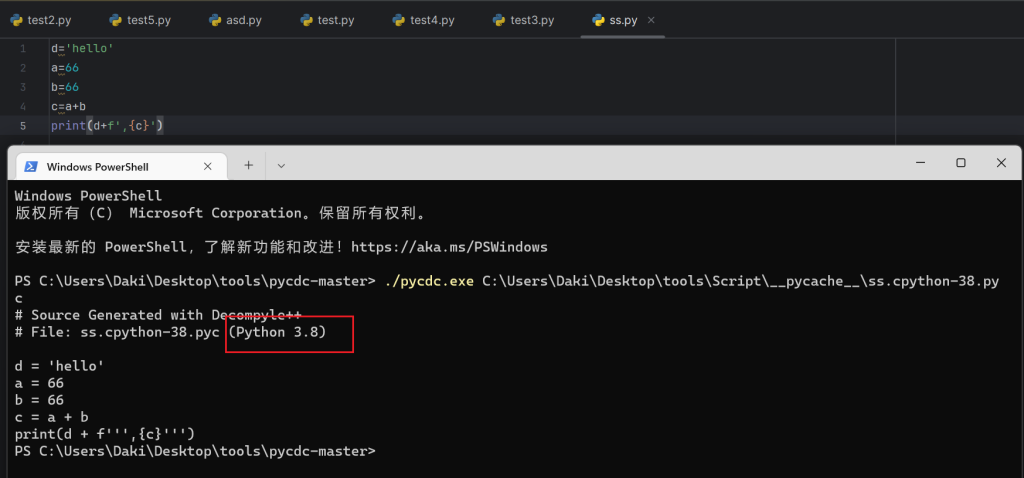
反编译没有什么问题。接下来我们再研究一下这个pyc文件。pyc文件的结构如下
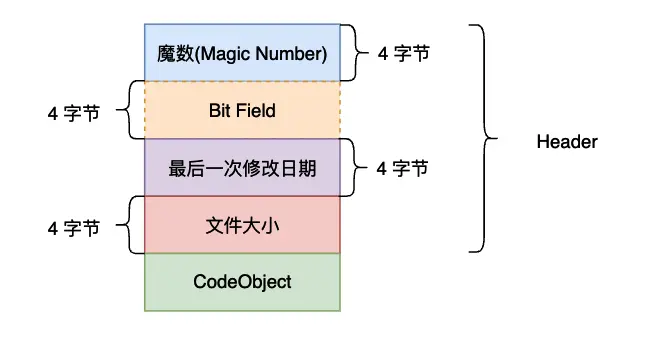
上图参考了以下博客
深入理解 python 虚拟机:pyc 文件结构 – 个人文章 – SegmentFault 思否
每一个Python版本编译出来的pyc都有其独特的魔数,这个魔数似乎就会影响反编译。
以下是各版本的Python对应的魔数
enum PycMagic {
MAGIC_1_0 = 0x00999902,
MAGIC_1_1 = 0x00999903, /* Also covers 1.2 */
MAGIC_1_3 = 0x0A0D2E89,
MAGIC_1_4 = 0x0A0D1704,
MAGIC_1_5 = 0x0A0D4E99,
MAGIC_1_6 = 0x0A0DC4FC,
MAGIC_2_0 = 0x0A0DC687,
MAGIC_2_1 = 0x0A0DEB2A,
MAGIC_2_2 = 0x0A0DED2D,
MAGIC_2_3 = 0x0A0DF23B,
MAGIC_2_4 = 0x0A0DF26D,
MAGIC_2_5 = 0x0A0DF2B3,
MAGIC_2_6 = 0x0A0DF2D1,
MAGIC_2_7 = 0x0A0DF303,
MAGIC_3_0 = 0x0A0D0C3A,
MAGIC_3_1 = 0x0A0D0C4E,
MAGIC_3_2 = 0x0A0D0C6C,
MAGIC_3_3 = 0x0A0D0C9E,
MAGIC_3_4 = 0x0A0D0CEE,
MAGIC_3_5 = 0x0A0D0D16,
MAGIC_3_5_3 = 0x0A0D0D17,
MAGIC_3_6 = 0x0A0D0D33,
MAGIC_3_7 = 0x0A0D0D42,
MAGIC_3_8 = 0x0A0D0D55,
MAGIC_3_9 = 0x0A0D0D61,
MAGIC_3_10 = 0x0A0D0D6F,
MAGIC_3_11 = 0x0A0D0DA7,
MAGIC_3_12 = 0x0A0D0DCB,
INVALID = 0,
};第二个Bit Field,网上文章说这个字段的主要作用是为了将来能够实现复现编译结果,是在Pythond的后期版本出现的,我Python3.8和Python3.11得到的pyc这里都是零,这应该是正常的现象,我们不关注这里。
第三个和第四个的最后一次修改日期和文件大小指的是py源文件的属性,而不是pyc文件的属性。
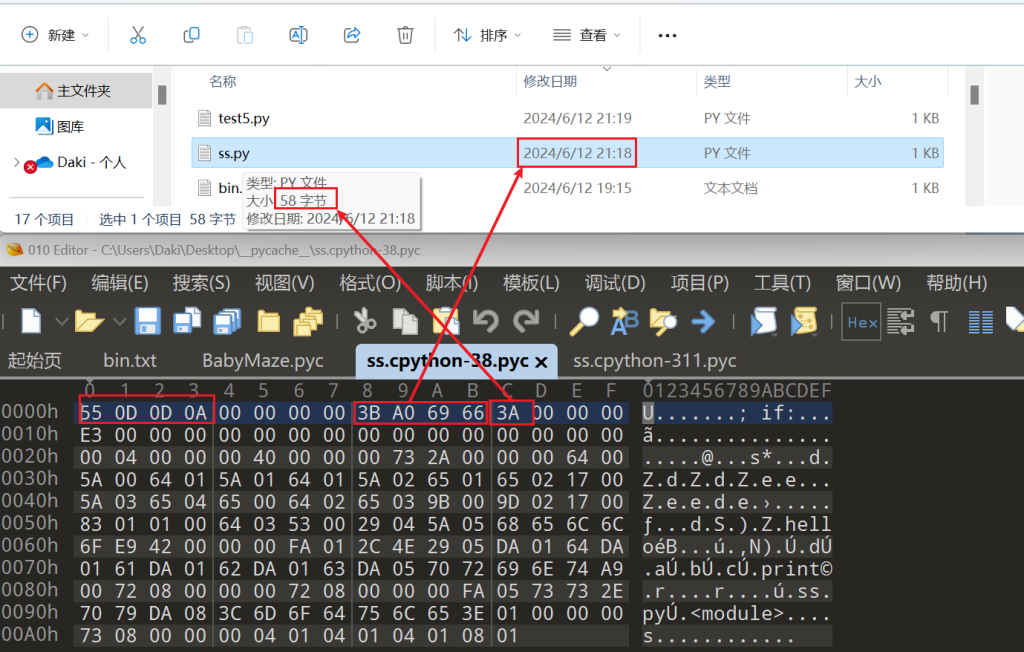
这里是小端序的存储方式,0x0A0D0D55高位数据放在高地址,魔术字就是前四个字节,第8到第12个字节是时间戳,然后3A就等于58,就是py源文件的大小。上面的16个字节组成了pyc的Header。
然后后面的就是我们需要重点关注的PyCodeObject对象,它存放在pyc是已经序列化的数据。它的结构如下
typedef struct {
PyObject_HEAD /* 头部信息, 我们看到真的一切皆对象, 字节码也是个对象 */
int co_argcount; /* 可以通过位置参数传递的参数个数 */
int co_posonlyargcount; /* 只能通过位置参数传递的参数个数, Python3.8新增 */
int co_kwonlyargcount; /* 只能通过关键字参数传递的参数个数 */
int co_nlocals; /* 代码块中局部变量的个数,也包括参数 */
int co_stacksize; /* 执行该段代码块需要的栈空间 */
int co_flags; /* 参数类型标识 */
int co_firstlineno; /* 代码块在对应文件的行号 */
PyObject *co_code; /* 指令集, 也就是字节码, 它是一个bytes对象 */
PyObject *co_consts; /* 常量池, 一个元组,保存代码块中的所有常量。 */
PyObject *co_names; /* 一个元组,保存代码块中引用的其它作用域的变量 */
PyObject *co_varnames; /* 一个元组,保存当前作用域中的变量 */
PyObject *co_freevars; /* 内层函数引用的外层函数的作用域中的变量 */
PyObject *co_cellvars; /* 外层函数中作用域中被内层函数引用的变量,本质上和co_freevars是一样的 */
Py_ssize_t *co_cell2arg; /* 无需关注 */
PyObject *co_filename; /* 代码块所在的文件名 */
PyObject *co_name; /* 代码块的名字,通常是函数名或者类名 */
PyObject *co_lnotab; /* 字节码指令与python源代码的行号之间的对应关系,以PyByteObject的形式存在 */
//剩下的无需关注了
void *co_zombieframe; /* for optimization only (see frameobject.c) */
PyObject *co_weakreflist; /* to support weakrefs to code objects */
void *co_extra;
unsigned char *co_opcache_map;
_PyOpcache *co_opcache;
int co_opcache_flag;
unsigned char co_opcache_size;
} PyCodeObject;这里的内容来自下面这篇博客,介绍的很详细,甚至介绍了对象里面的每一个成员,但是我在这里没必要学习的那么详细,如果继续探讨下去,任何东西都没完没了了。
《深度剖析CPython解释器》10. Python中的PyCodeObject对象与pyc文件 – 古明地盆 – 博客园 (cnblogs.com)
pyc与marshal
既然pyc文件开头16个字节之后的是序列化的PyCodeObject对象,我们就可以利用marshal模块对其进行反序列化。代码如下
import marshal
f = open("ss.cpython-38.pyc", "rb").read()
obj = marshal.loads(f[16:])
#这边从16位开始取,前面的16个字节不包括在内,如果一起反序列化会报错
type(obj)
#输出<class 'code'>
dir(obj)
#输出['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags', 'co_freevars', 'co_kwonlyargcount', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals', 'co_posonlyargcount', 'co_stacksize', 'co_varnames', 'replace']我们对反序列化后的代码对象用type()和dir()函数看一下,可以看到,返回的数据类型是代码对象,用dir()函数查看它的属性,前面PyCodeObject结构中的成员几乎都出现了。我们可以直接看一下其中的属性

确实存的是变量,这里用的源文件还是前面那个ss.py。你自己也可以查看其他的属性。
我们在反序列化后也可以用exec执行源代码中的Python代码

我们也可以导入dis模块,然后用dis.dis()函数可以直接显示py源文件的字节码
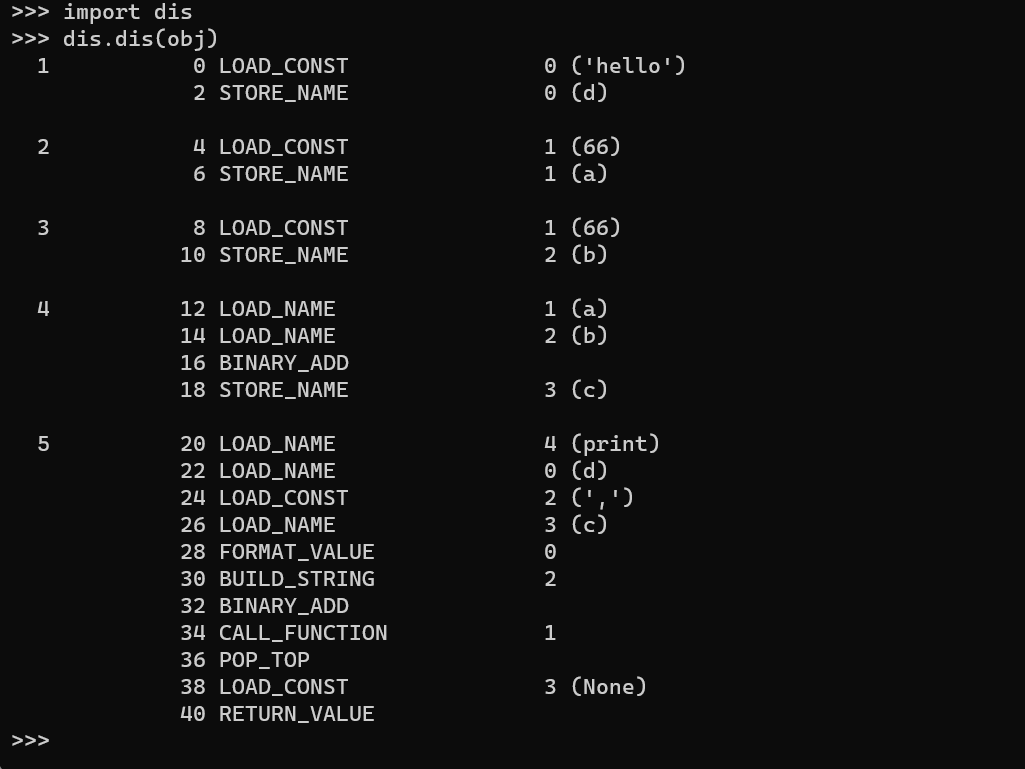
这个函数我们用的比较多,因为可能会有各种各样的原因,使得我们无法对pyc文件进行反编译,这时候我们就可以用marshal模块反序列化之后,用dis模块的dis函数分析字节码,直接分析字节码有时候可以达成我们的目的,有时候也可以知道为什么会反编译错误,比如字节码里面可能加了跳转花指令。