这是攻防世界里面之前的比赛,上次做了一下XCTF的比赛题目,难度太高了,简直就是坐牢,但是越难就越能学到知识,我就看了一下之前比赛的题目。
第一次做Rust语言的逆向题目,只能跟着Writeup来看,其实我很好奇那些逆向大佬们是做题目之前已经学过这门语言,还是说做题的时候才去查资料的。
题目给的可执行文件,应用图标长这样。

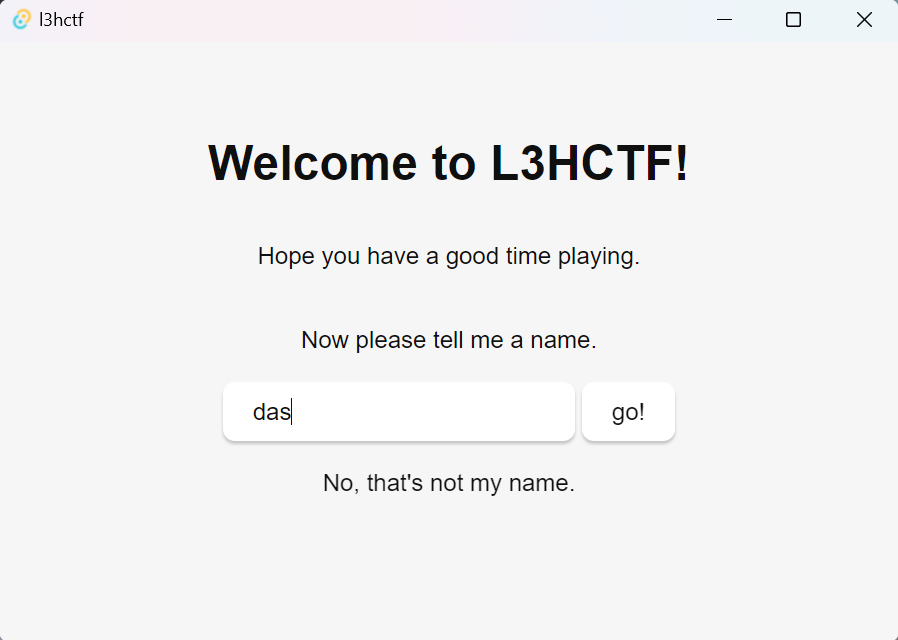
打开来,应用界面还挺简洁好看的,没有用MFC写的应用的那种僵硬的感觉,应用要求我们输入一个name,输错会提示 No, that’s not my name,如图
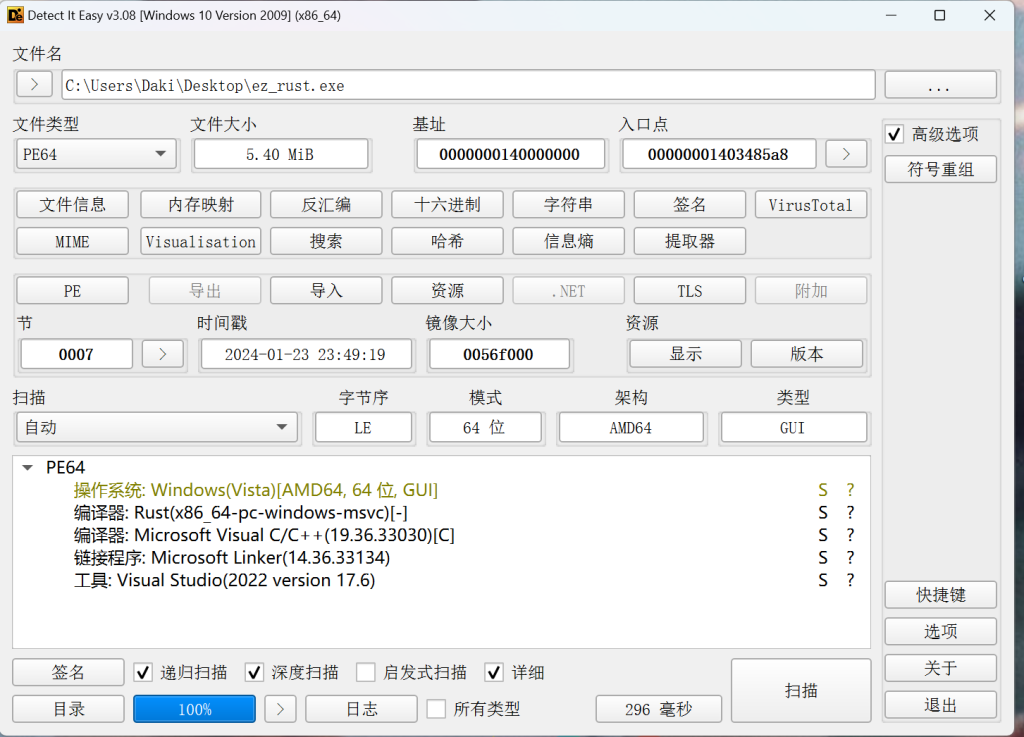
用DIE查一下信息,如图
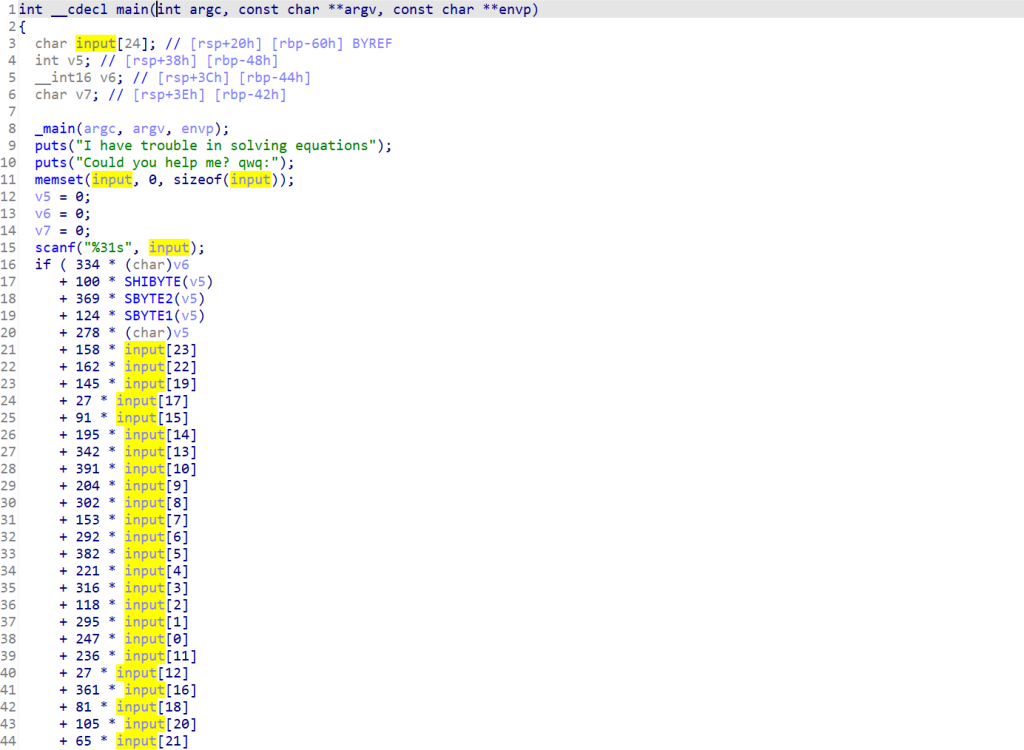
确实是Rust,然后再用IDA打开来,发现有很多的函数,分析的时候也比正常久,Strings window也有很多的字符信息,如图
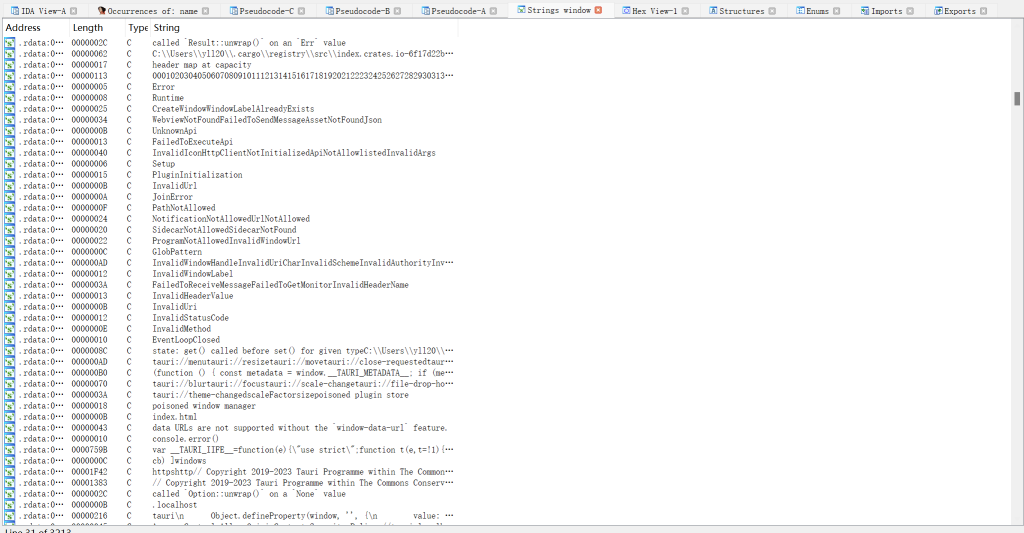
第一反应是感觉有点像那种用PyInstaller打包的Python可执行程序,Strings window里面也是有很多的字符信息,看来这种不是逆向传统语言的都有些共同点,自己又找了一下IDA,发现并没有什么题目信息,我猜测这题可能也是像Python逆向的一样,可能要用其他工具或者其他方法来解决。
看了Writeup,果然如此,看了很多战队的Writeup,都提供了这个博客的文章来学习,这题目考了Rust的Tauri 框架,链接如下:
Tauri 框架的静态资源提取方法探究 | yllhwa’s blog
我还百度了一些其他关于Tauri 框架的文章,我的理解就是Rust的这个框架可以用网页前端语言的三件套HTML、CSS和JavaScript,来编写桌面应用的。
我们就按照上面那篇博客,先在Strings window搜索/index.html,果然有
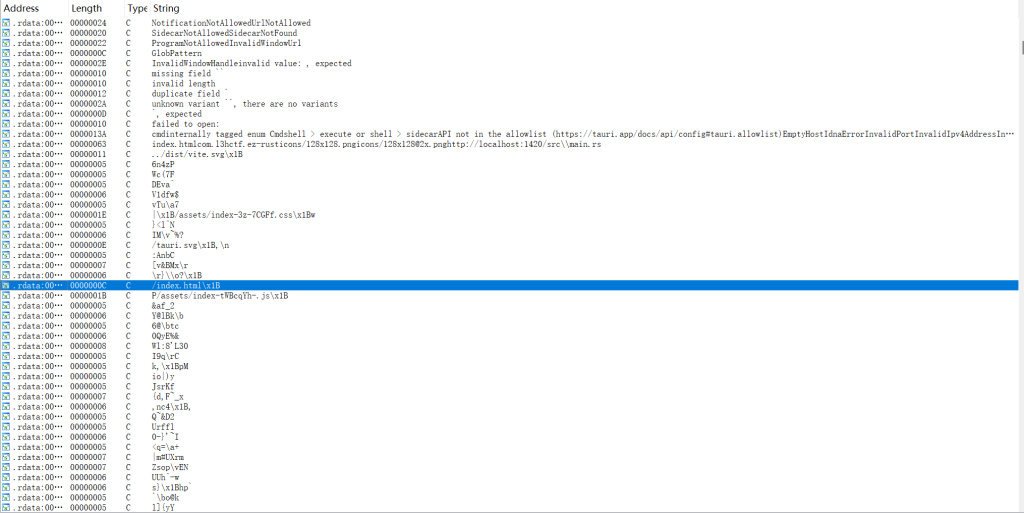
然后直接点击去,查看引用,来到这个界面。
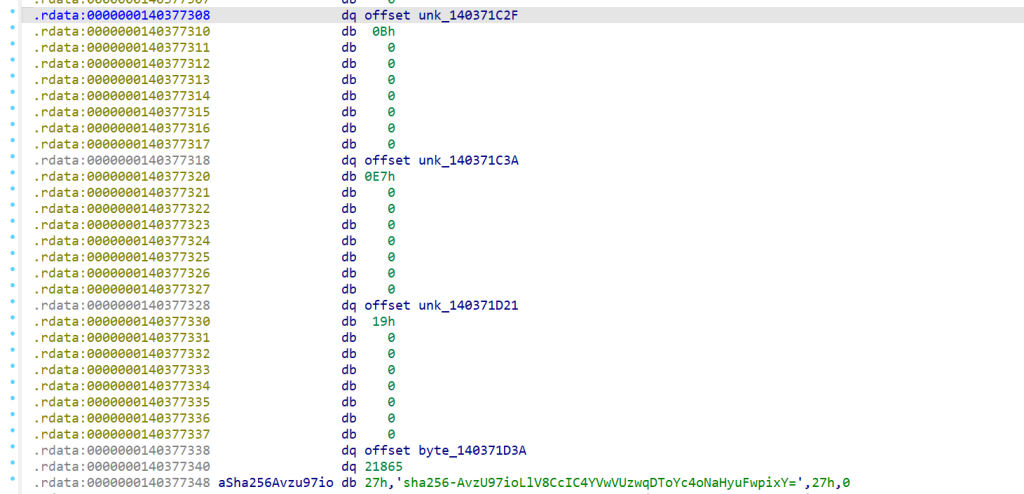
按照上面博客的说法,这里有两组,每组四个数据,每一组的第一个地址点进去是文件名,地址后面就是文件名的长度,比如第一个0Bh是index文件名的长度,第二个地址就是文件,后面的数据是文件的长度,比如上面的0E7h。做出以下批注。

这样就很清晰了,第一个地址点进去,文件名是/index.html,,第三个地址点进去,文件名是/assets/index-tWBcqYh-.js,这道题应该是提取.js文件,然后里面的源码估计有要解决的问题。
别看我现在思路清晰,问了好久大佬好多问题,一开始我连怎么dump文件内容我都不知道,我还傻傻的点进去第三个地址处往下dump,直接导致脚本报错。
第三个地址是文件名,不能包括在里面,所以我们直接点进第四个地址处.

选中地址第一个元素处,IDA左上角Edit->Array,然后输入21865,把数据聚在一起,这样方便我们接下来的dump,然后继续选中第一个元素,IDA左上角Edit->Export data,选Export as raw bytes,然后Output file的文件格式都行,这就是dump的操作!如图
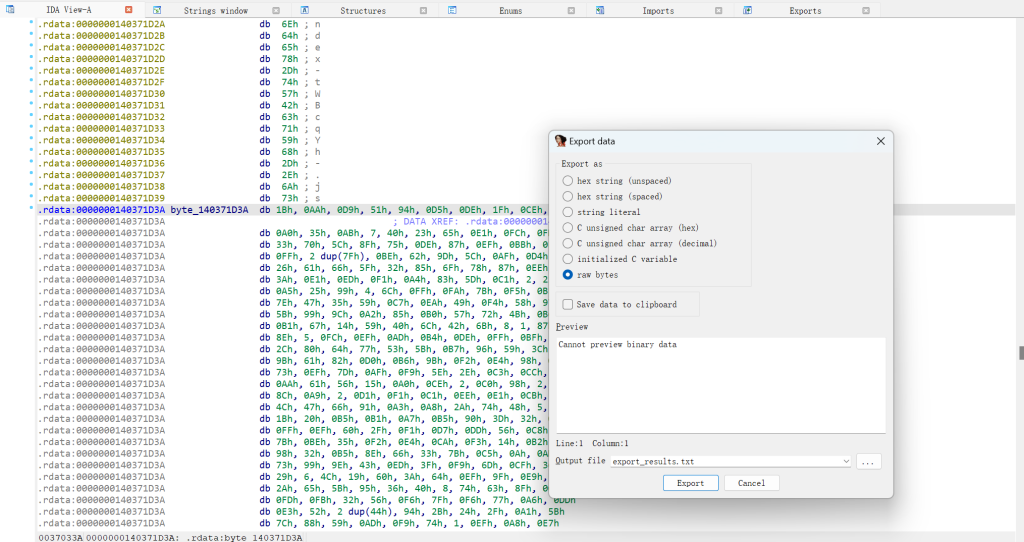
然后用脚本
import brotli
content = open("export_results.txt", "rb").read()
print(len(content))
decompressed = brotli.decompress(content)
open("dump", "wb").write(decompressed)提前创建好一个dump文件,然后再换成记事本打开就是一堆也许是JavaScript的代码,
然后找到关键代码,但是这里一坨,巨难分析,看别人的Writeup,是将JS格式化,我就去百度了一下,然后格式化了一下,发现真的好看了很多,而且应该是把代码变了吧,我也不清楚JS格式化是什么意思。
以下是关键的代码:
function s(o, i = "secret") {
for (var c = "", u = i.length, d = 0; d < o.length; d++) {
var h = o.charCodeAt(d),
x = i.charCodeAt(d % u),
w = h ^ x;
c += String.fromCharCode(w)
}
return c
}
async function r() {
if (n.value === "") {
t.value = "Please enter a name.";
return
}
btoa(s(n.value)) === "JFYvMVU5QDoNQjomJlBULSQaCihTAFY=" ? t.value = "Great, you got the flag!" : t.value = "No, that's not my name."
}查了一下,charCodeAt() 是 JavaScript 中的一个字符串方法,用于获取指定位置字符的 Unicode 编码。也就是Python的ord( ),最后的比较字符串很明显是Base64编码,应该要先解码一次。
脚本如下:
import base64
en=base64.b64decode('JFYvMVU5QDoNQjomJlBULSQaCihTAFY=')
flag=''
s=b'secret'
#这里必须要是字节字符串,因为前面Base64解码得到的也是字节字符串
for i in range(len(en)):
flag+=chr(en[i]^s[i%6])
print(flag)
#输出W3LC0M3_n0_RU57_AnyM0r3所以flag为L3HCTF{W3LC0M3_n0_RU57_AnyM0r3}



受教了orz