这一题,是 Reverse 方向的,很像广州大学第三届方班预备班 X 网安学会 CTF 新生赛 Reverse 里面的一题,后面再复盘那一题
用 IDA 打开给的 PZthon.exe 文件,没什么关键函数,直接 shift + F12 看 Strings Window,发现字符串数据非常多,没什么特别的字符串,要说特别的就下面这几个
为什么说像广州大学新生赛的那一题,像就像在这里,当时做那一题时这也有图里面的这两种字符串,星期、月份还有 26 个大小写字母都出现了,当时作为小白啥也不懂,以为是关键数据,这困惑了我很久。好吧,现在也是小白,图中的这些字符串我现在也不明白为啥会出现。这题反正也是没思路,因为广州大学新生赛那一题我也还没搞懂呢。直接看 Writeup
NewStarCTF 2023 Week2 官方 WriteUp(转载)-CSDN 博客
Writeup 说如图这些是 Python 的痕迹,考点也就是 py 打包成的 exe,其实题目的标题也有提示了。学习了一下,是指将 python 的.py 源代码文件打包成.exe 可执行文件,作用呢是可以使我们的程序在没有安装 Python 解释器的环境中运行。需要依靠类似 PyInstaller 等工具。
第一次接触这种类型的题目,所以啥也不会也正常吧。
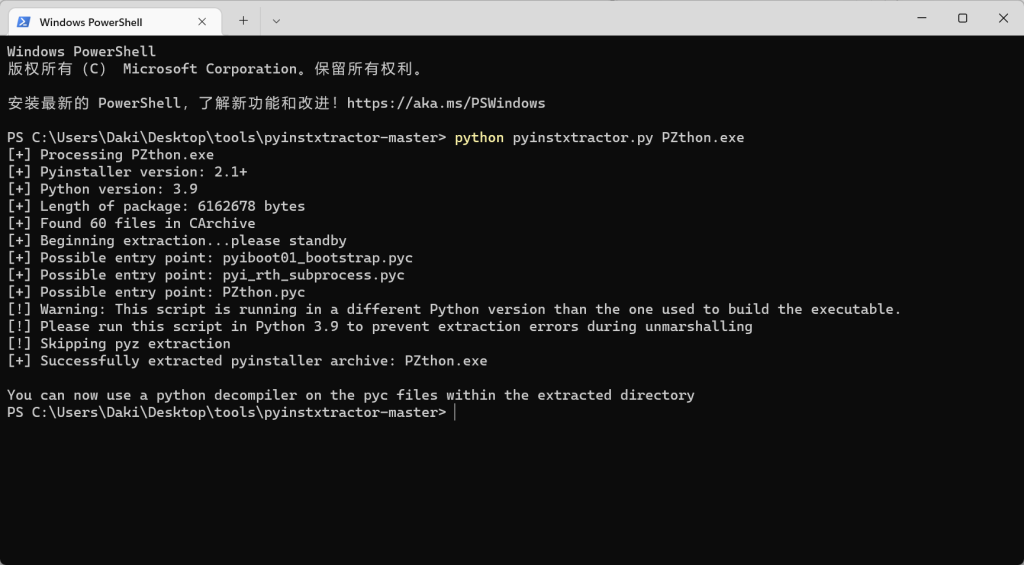
所以按照 Writeup,我们要做的,就是依据.exe 文件获得它的 python 源代码吧,毕竟 flag 的线索大概率在源代码里,利用到解包工具 pyinstxtractor,又是第一次接触,不过安装使用都不难,Writeup 里面给了下载链接,直接解包
在同级目录下可以找到 PZthon.exe_extracted 文件夹,在里面找到 PZthon.pyc,该文件就是 python 文件的字节码文件。
那什么又是.pyc 文件呢?
python 运行经过了两步操作:
将源代码编译成为 “字节码” 转发 “字节码” 到 “虚拟机”
可以理解为翻译,把 print(hello world) 翻译成字节码,字节码会保存在后缀名是.pyc 的文件里,这文件其实就是编译后的.py 源代码。
这些字节码相较于源代码,运行起来速度要快得多。为什么?
pyc 文件是由.py 文件经过编译后生成的字节码文件在下一次运行程序时,如果在上次保存了字节码之后没有修改过源代码了,Python 就会加载.pyc 文件并且跳过编译这个步骤,就省去了编译的过程,节省了时间 。其加载速度就相对于之前的.py 文件有所提高,而且还可以实现源码隐藏 ,以及一定程度上的反编译 。因此,不同版本的 python 可能运行不了同一个.pyc 文件。
在这里又牵扯到 “字节码” 和 “虚拟机” 两个概念,就不多扩展先。这两个概念其实 Java 语言里面也是有的,而且 Java 也有类似.pyc 的字节码文件.class,后面是会遇到 Java 的反编译题目的
所以.pyc 文件确实是可以反编译回 python 的源代码的,我们直接用 pycdc 反编译,得到如下代码
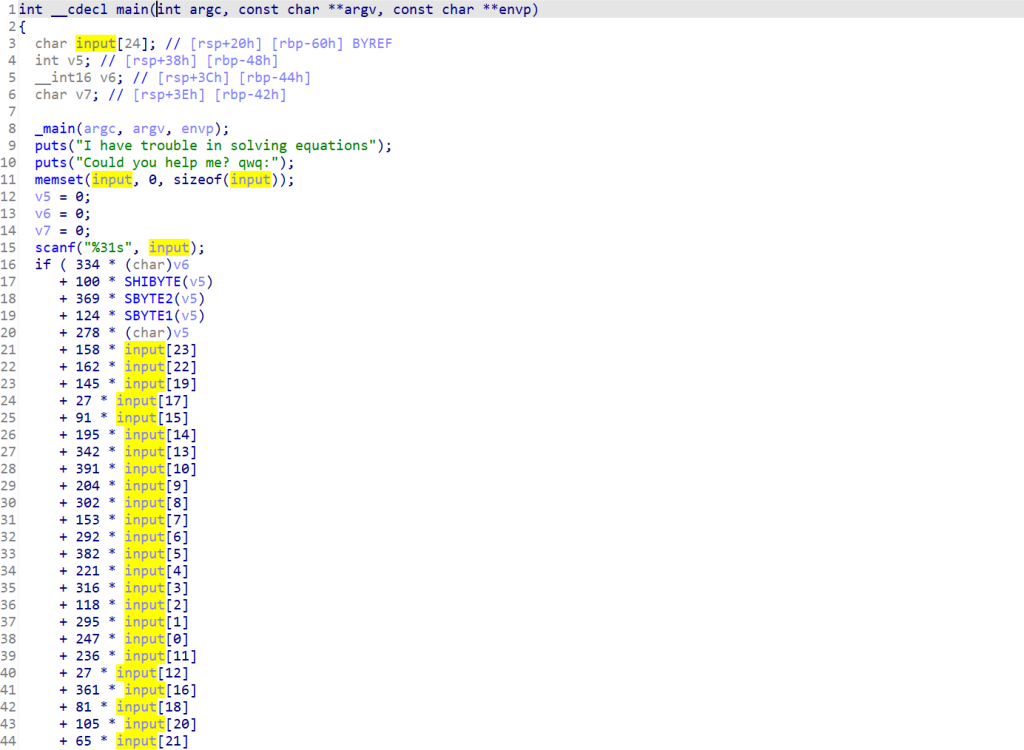
def hello ():
art = '\n ___ \n // ) ) / / // ) ) // | | / / // | | \\ / / \\ / / \n //___/ / / / // //__| | / / //__| | \\ / \\ / / \n / ____ / / / // ____ / ___ | / / / ___ | / / \\/ / \n // / / // / / // | | / / // | | / /\\ / / \n// / /___ ((____/ / // | | / /____/ / // | | / / \\ / / \n \n / / // / / || / / // / / / / /__ ___/ || / | / / // ) ) \n / / //____ || / / //____ / / / / || / | / / // / / \n / / / ____ || / / / ____ / / / / || / /||/ / // / / \n / / // ||/ / // / / / / ||/ / | / // / / \n / /____/ / //____/ / | / //____/ / / /____/ / / / | / | / ((___/ / \n'
print(art)
return bytearray (input ('Please give me the flag: ' ).encode())
enc = [
115 ,
121 ,
116 ,
114 ,
110 ,
76 ,
37 ,
96 ,
88 ,
116 ,
113 ,
112 ,
36 ,
97 ,
65 ,
125 ,
103 ,
37 ,
96 ,
114 ,
125 ,
65 ,
39 ,
112 ,
70 ,
112 ,
118 ,
37 ,
123 ,
113 ,
69 ,
79 ,
82 ,
84 ,
89 ,
84 ,
77 ,
76 ,
36 ,
112 ,
99 ,
112 ,
36 ,
65 ,
39 ,
116 ,
97 ,
36 ,
102 ,
86 ,
37 ,
37 ,
36 ,
104 ]
data = hello()
for i in range (len (data)):
data[i] = data[i] ^ 21
if bytearray (enc) == data:
print('WOW!!' )
else :
print('I believe you can do it!' )
input ('To be continue...' )
我一开始写的脚本是这样的,但是一直报错,’ord () expected string of length 1, but int found‘,但是我打印了一次 date,发现 date 里面也没数字啊
enc = [0x73 , 0x79 , 0x74 , 0x72 , 0x6e , 0x4c , 0x25 , 0x60 , 0x58 , 0x74 , 0x71 , 0x70 , 0x24 , 0x61 , 0x41 , 0x7d , 0x67 , 0x25 , 0x60 ,
0x72 , 0x7d , 0x41 , 0x27 , 0x70 , 0x46 , 0x70 , 0x76 , 0x25 , 0x7b , 0x71 , 0x45 , 0x4f , 0x52 , 0x54 , 0x59 , 0x54 , 0x4d , 0x4c ,
0x24 , 0x70 , 0x63 , 0x70 , 0x24 , 0x41 , 0x27 , 0x74 , 0x61 , 0x24 , 0x66 , 0x56 , 0x25 , 0x25 , 0x24 , 0x68 ]
date =bytearray(enc)
#在这里print (date )的话结果是bytearray(b"sytrnL%`Xtqp$aA}g%`r}A\'pFpv%{qEORTYTML$pcp$A\'ta$fV%%$h" )
for i in range(len (enc)):
date [i]=chr(ord(date [i])^21 )
print (date )
后面问了学校的大佬,才又又又学到了小知识,像这种 bytes,bytearray,long_to_bytes 的函数,最终输出来的字节串,里面的数据都是以 int 的形式存储的,但是输出出来会以 b”some string” 的形式显现出来,我觉得可以用以下 python 代码来解释就可以明白了
enc = [0x73, 0x79, 0x74, 0x72, 0x6e, 0x4c, 0x25, 0x60, 0x58, 0x74, 0x71, 0x70, 0x24, 0x61, 0x41, 0x7d, 0x67, 0x25, 0x60,
0x72, 0x7d, 0x41, 0x27, 0x70, 0x46, 0x70, 0x76, 0x25, 0x7b, 0x71, 0x45, 0x4f, 0x52, 0x54, 0x59, 0x54, 0x4d, 0x4c,
0x24, 0x70, 0x63, 0x70, 0x24, 0x41, 0x27, 0x74, 0x61, 0x24, 0x66, 0x56, 0x25, 0x25, 0x24, 0x68]
date=bytearray(enc)
print(date)
# 输出结果为 bytearray(b"sytrnL%`Xtqp$aA }g%`r}A\'pFpv%{qEORTYTML$pcp$A \'ta$fV %%$h " )
print(date[0])
# 输出结果为数字115
date[0]=65
print(date)
# 输出结果为 bytearray(b"AytrnL%`Xtqp$aA }g%`r}A\'pFpv%{qEORTYTML$pcp$A \'ta$fV %%$h " )
这里看明明输出是 b”sytrnL%`Xtqp$aA} g%`r} A\’pFpv%{qEORTYTML$pcp$A\’ta$fV%%$h”,但是打印出来 date [0] 却是 115,也就是字母 s 在 Ascii 码表中对应的值,把它直接改为 A 在 Ascii 码表中对应的值 65,就显现出 A 了。
所以改进脚本如下
enc = [0x73 , 0x79 , 0x74 , 0x72 , 0x6e , 0x4c , 0x25 , 0x60 , 0x58 , 0x74 , 0x71 , 0x70 , 0x24 , 0x61 , 0x41 , 0x7d , 0x67 , 0x25 , 0x60 ,
0x72 , 0x7d , 0x41 , 0x27 , 0x70 , 0x46 , 0x70 , 0x76 , 0x25 , 0x7b , 0x71 , 0x45 , 0x4f , 0x52 , 0x54 , 0x59 , 0x54 , 0x4d , 0x4c ,0x24 , 0x70 , 0x63 , 0x70 , 0x24 , 0x41 , 0x27 , 0x74 , 0x61 , 0x24 , 0x66 , 0x56 , 0x25 , 0x25 , 0x24 , 0x68 ]
date =bytearray(enc)
for i in range(len (enc)):
date [i]=(date [i])^21
print (date )
#输出结果为 bytearray(b'flag{Y0uMade1tThr0ughT2eSec0ndPZGALAXY1eve1T2at1sC001}' )
因此 flag 即为 flag {Y0uMade1tThr0ughT2eSec0ndPZGALAXY1eve1T2at1sC001}