今天通过《逆向工程核心原理》学习一下PE文件格式,先放一篇别的大佬写的
关于逆向工程核心原理-PE文件 – P.Z’s Blog (ppppz.net)
1.介绍
PE文件时Windows操作系统下使用的可执行文件格式。它的全称是Portable Executable。
Portable的意思是便携的、轻便的,Executable的意识是可执行的,据说由第一个单词是因为一开始设计PE文件是来提高程序在不同程序上的移植性,但最后只在Windows之中使用。

可以看到PE文件不仅仅局限于我们所熟知的exe文件。还有上图中的几种。
VA、RVA、RAW、ImageBase
在学习PE文件格式之前我们需要了解VA、RVA、RAW、ImageBase这四个概念。
PE格式第三讲扩展,VA,RVA,FA(RAW),模块地址的概念 – iBinary – 博客园
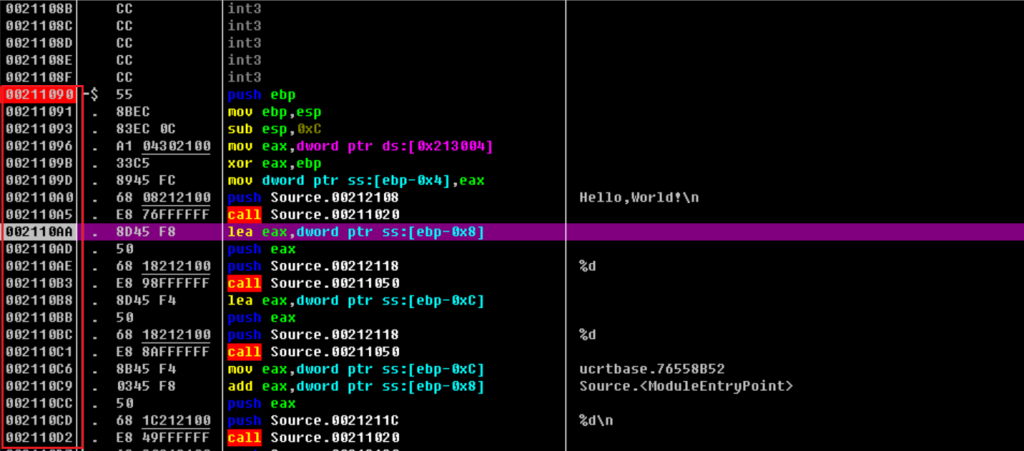
VA(Virtual Address)指的是进程虚拟内存的绝对地址,是程序被加载到内存中的地址,比如我在OD中打开一个PE文件,如图,左侧的地址即为VA
ImageBase即基准位置,就是PE文件加载到内存的时候,开头的地址,我们可以通过OD查看
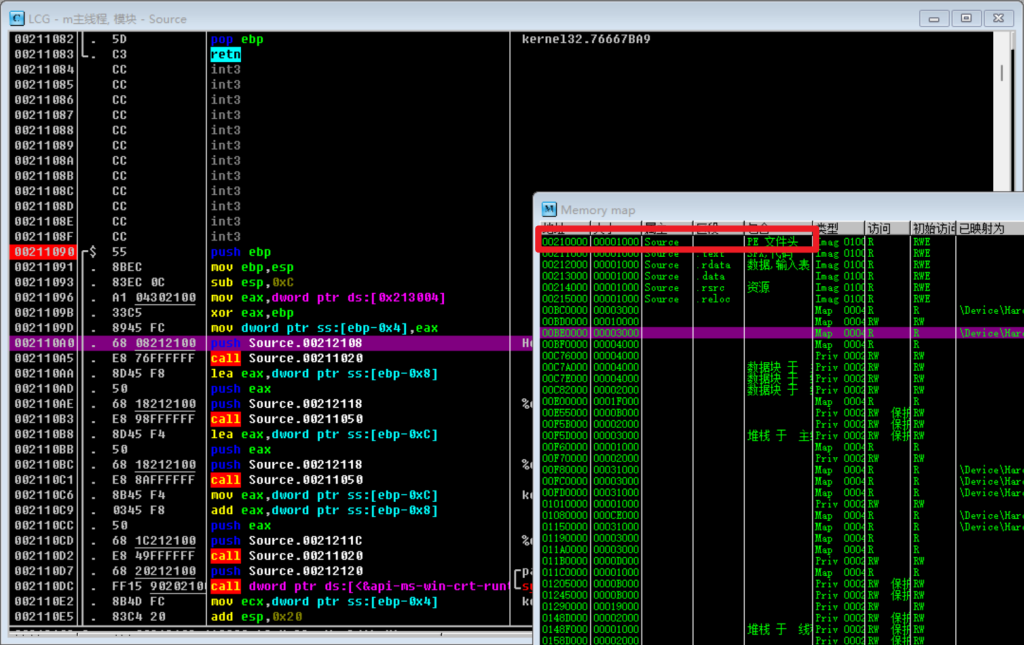
如上图我编写的程序的ImageBase就是210000,这里开头会载入我们程序的PE文件头。当然ImageBase最经典的应该还是0x401000。
RVA(Relative Virtual Address)相对虚拟地址,指从某个基准地址开始的相对的地址,VA与RVA满足下列的换算关系:
RVA + ImageBase = VA
比如上面图片的程序,mian函数开头的RVA为0x211090 – 0x210000 = 0x1090
在PE头内部的信息大多以RVA的形式存在,因为PE文件(主要是DLL)加载到进程的虚拟地址时,这个位置可能已经加载了其他的PE文件,已经被占用了。此时必须通过重定位加载到内存其他的空白位置 ,使用VA当然无法做到这一点,因为VA处已经被占用,但是利用RVA,程序可以选择一个基准位置,然后重定位进行加载,相对于基准位置的相对地址没有变化,就能正常访问到指定信息。
讲解PE文件经常出现 “映像(Image)” 这一个术语,PE文件加载到内存中时,文件不会原封不动地加载,而要根据节区头中定义的节区起始地址、节区大小等加载。因此,磁盘文件当中的PE与内存当中的PE具有不同的形态,我们将加载到内存中的形态称为映像来区别。
PE文件加载到内存时,每个节区头都要能准确完成内存地址与文件偏移间的映射,这种映射一般称为RVA to RAW。
RVA可以理解为内存偏移,RAW可以理解为文件偏移。
根据后文的IMAGE_SECTION_HEADER结构体,RVA和RAW之间的转换符合以下关系
RAW – PointerToRawData = RVA – VirtualAddress
如图
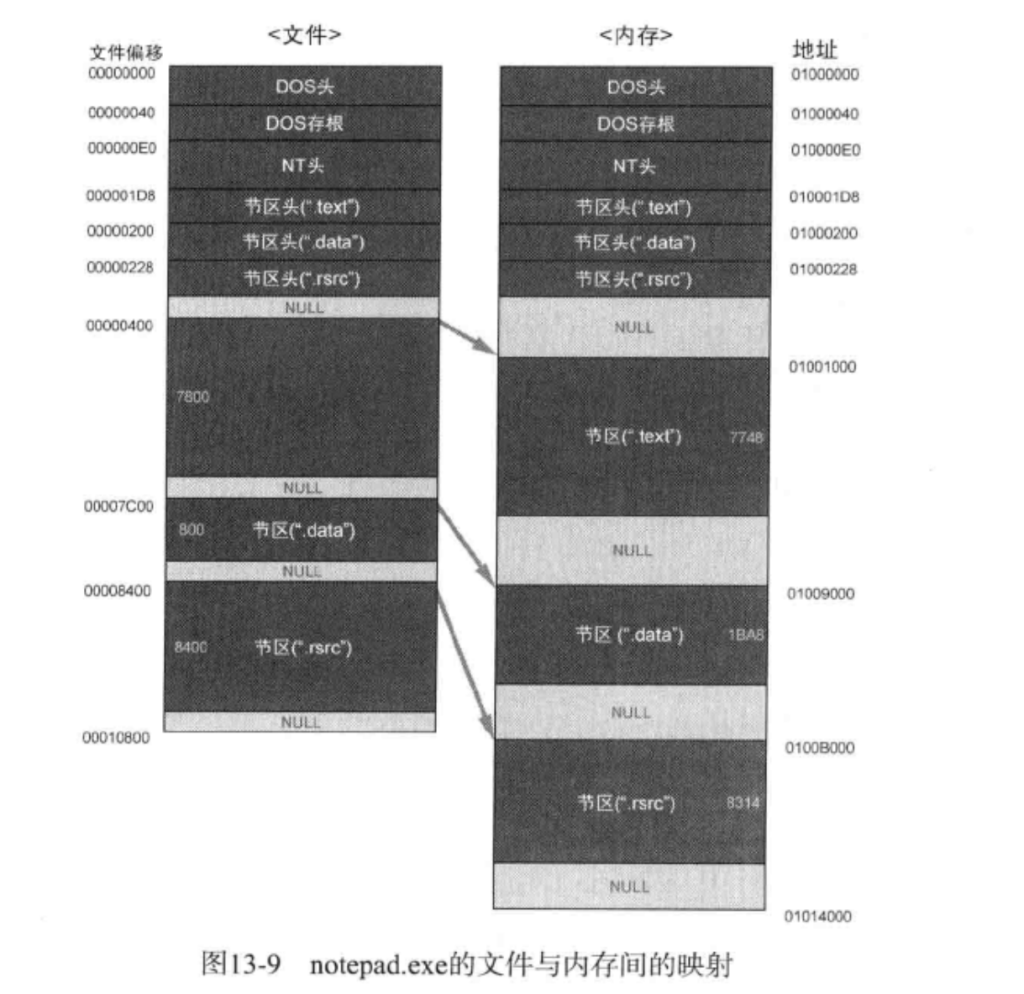
左侧是文件偏移,从零开始,右侧的地址即使VA,从0x1000000开始,这个0x1000000就是ImageBase
假设RVA为5000,即右侧地址0x1005000处,位于第一个节区(“.text”)的范围0x1001000到0x100874B之间
RAW = 5000(RVA) – 1000(VirtualAddress) + 400(PointerToRawData) = 4400
VirtualAddress即内存中的节区起始地址(RVA),PointerToRawData即磁盘文件中节区起始位置
当然这里还有一种情况,比如当RVA为ABA8时,处于第二个节区(.data)
RAW = ABA8(RVA) – 9000(VirtualAddress) + 7C00(PointerToRawData) = 97A8
然而97A8在文件偏移中在第三个节区(.rsrc)的位置,这显然不对,而出现这种情况的原因是因为第二个节区的VirtualSize(内存中节区所占大小)要比SizeOfRawData(磁盘文件中节区所占大小)大
这里我们理解一下,上面的计算RAW的等式,其实说明在一个节区之内,RVA和内存节区起始地址之间的差值等于RAW和磁盘空间中节区起始地址的差值,一般情况下可能是VirtualSize小于SizeOfRawData,当出现相反情况时,磁盘空间中节区起始地址加上RVA和内存节区起始地址之间的差值之后就会越过节区的界限,用公式说明大概就是
PointerToRawData + ( RVA – VirtualAddress ) > PointerToRawData + SizeOfRawData
( RVA – VirtualAddress ) > SizeOfRawData
2.基本结构
这本书以自带的notepad.exe程序来分析它的PE格式
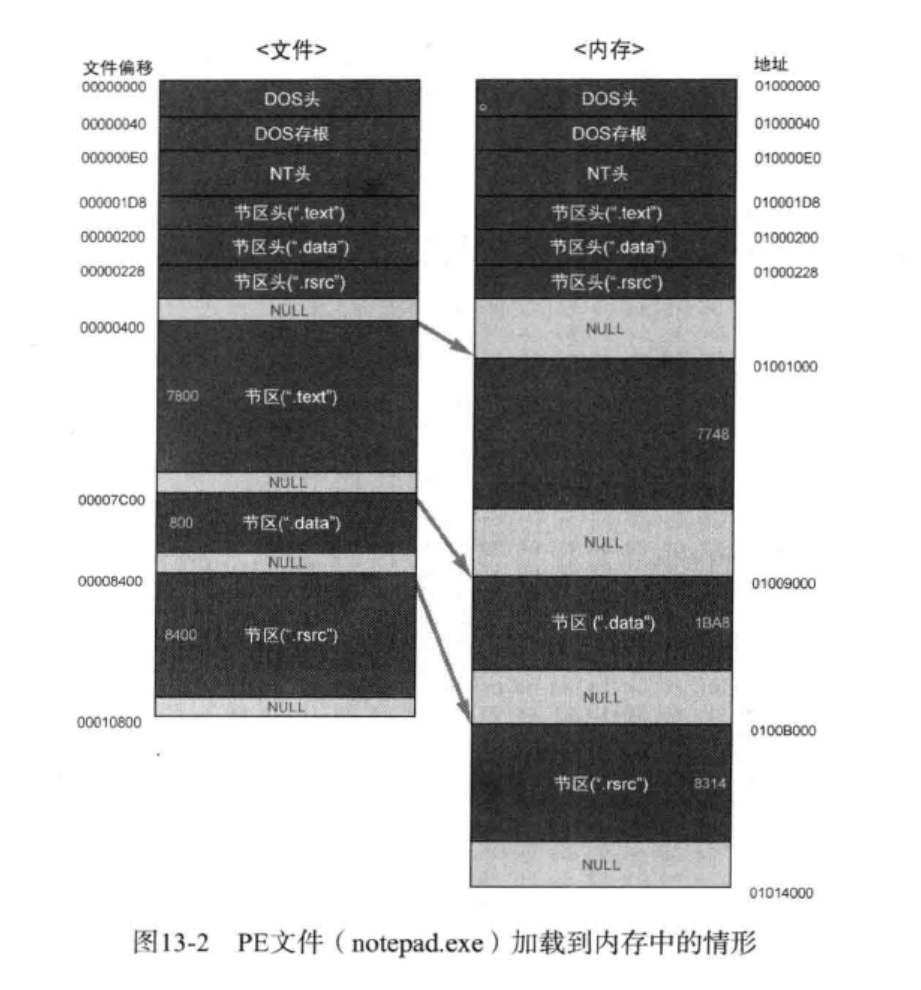
图片是程序加载到内存中的情形,从DOS头到节区头的部分是PE头部分,其下的节区都叫做PE体,图中的数据在文件中用偏移(offset),在内存中则用虚拟地址来表示(Virtual Address)来表示。文件加载到内存时,如图中所示,节区的大小和位置会发生改变,文件的内容分为代码、数据、资源节。
上面的虚拟地址和节区啥的在IDA中倒是有所体现。
图中的NULL是NULL填充,看下面的描述

这里的思想我记得在学习汇编语言的时候有提过

大概是类似的思想,为了寻址的方便还有提高寻址的效率,我觉得是这样的,如果不是最小单位的倍数,那可能CPU就无法用地址来表示数据的位置了。
3.DOS头
微软早期为了兼容DOS文件,也就是十六位操作系统上的文件,在PE头的最前端增加了一个结构体IMAGE_DOS_HEADER,如下
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;这是在16位操作系统之下,所以总共有40个字节,该结构体有两个很重要的成员,就是第一个和最后一个需要重点关注,这两个的直接修改也会导致程序无法运行
WORD e_magic; //DOS签名:4D5A("MZ")
LONG E_lfanew; //指示NT头的偏移这个”MZ”我们逆向中通常用来判断一个程序是否是Windows可执行程序,关于它的来源


DOS头中除了这两个之外的其他数据修改似乎不会影响程序的打开
4.DOS存根
DOS存根在DOS头下面,大小不固定,即使没有,也可以正常运行,由代码和数据混合而成,下图为即为书中提供程序的DOS存根

文件偏移40到4D区域是汇编指令,只有在DOS环境中运行该指令,才会执行这里的代码,而在Windows中并不会运行该命令,我们可以用DOSBox打开试试,如图
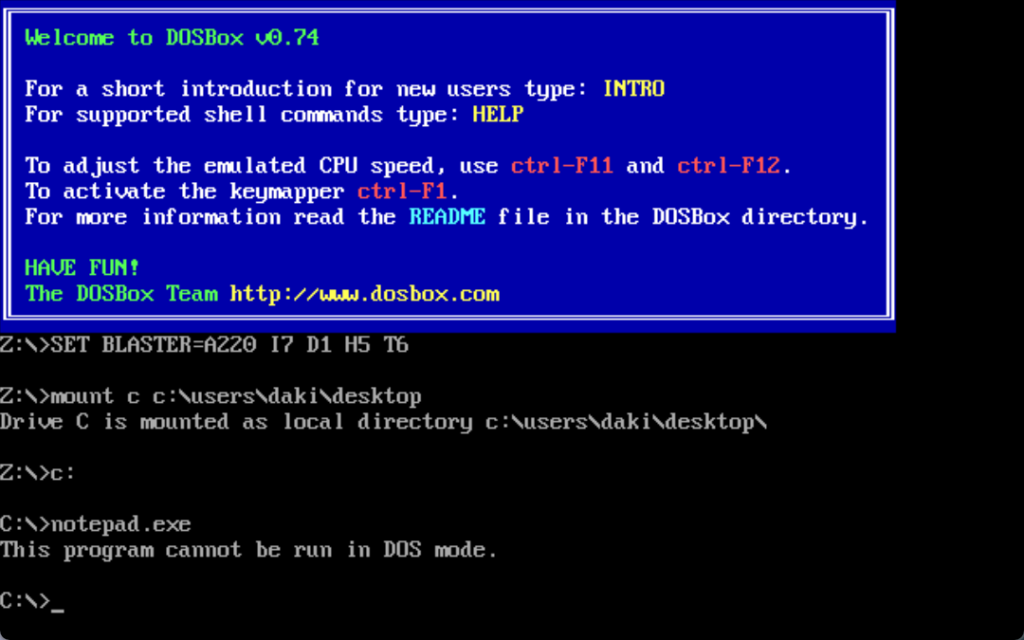
确实输出了存储在DOS存根中的字符串
5.NT头
NT头IMAGE_NT_HEADERS,结构体如下
typedef struct IMAGE_NT_HEADERS
{
DWORD Signature; //PE Signature : 50450000("PE"00)
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
}IMAGE_NT_HEADERS32,*PIMAGE_NT_HEADERS32;
结构体由签名、文件头、可选头组成
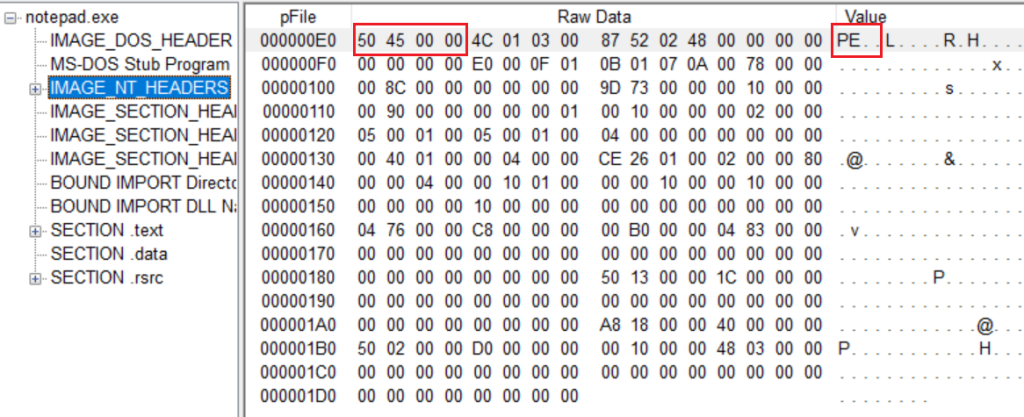
该结构体的大小为F8,相当大,签名的内容是固定的,如上图红圈内所示,即”PE”,和”MZ”的标识差不多。
NT头:文件头
文件头是表现文件大致属性的一个结构体
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;//CPU的架构类型
WORD NumberOfSections;//文件的节区数目
DWORD TimeDateStamp;//文件创建的用时间戳标识的日期
DWORD PointerToSymbolTable;//指向符号表(用于调试)
DWORD NumberOfSymbols;//符号表中符号的个数
WORD SizeOfOptionalHeader;//IMAGE_OPTIONAL_HEADER32结构大小
WORD Characteristics;//文件属性
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;每个CPU都有唯一的Machine码,它指明了CPU的架构

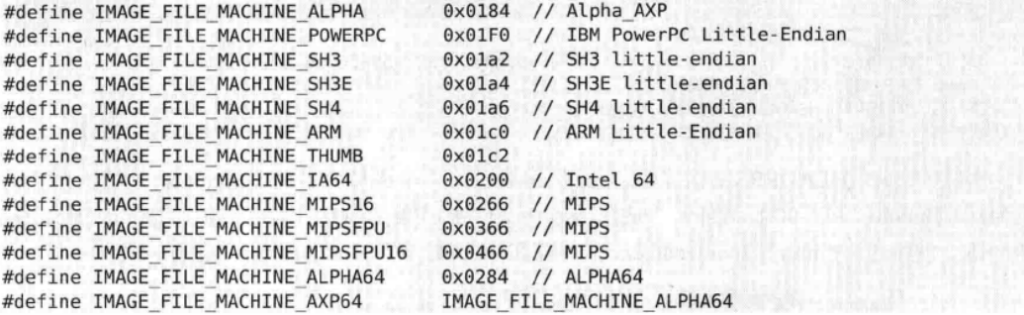
然后是NumberOfSections,用来指出文件当中存在的节区数量,这个值一定要大于零,并且如果修改它,使它的数量与实际节区不同时,会发生运行错误。如图
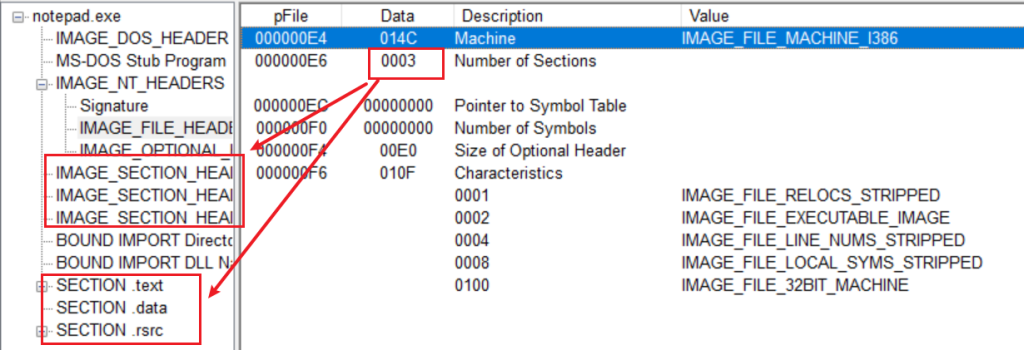
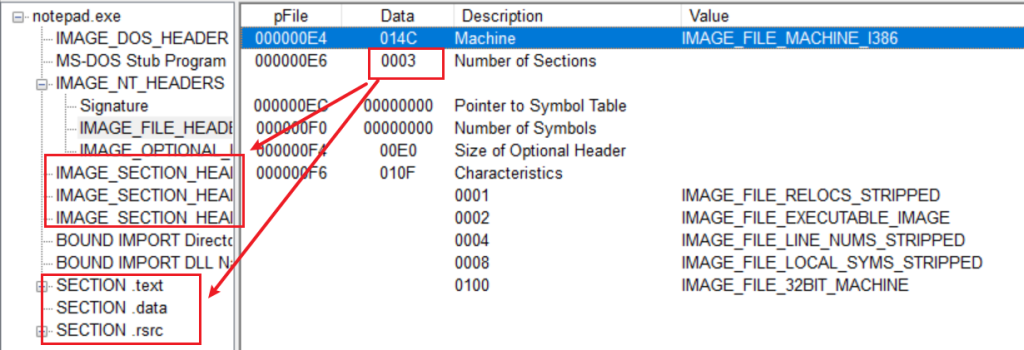
NT头的最后一个结构体是IMAGE_OPTIONAL_HEADER32,而文件头的倒数第二个成员SizeOfOptionalHeader用来指明IMAGE_OPTIONAL_HEADER32结构体的大小,看它名字就知道了。
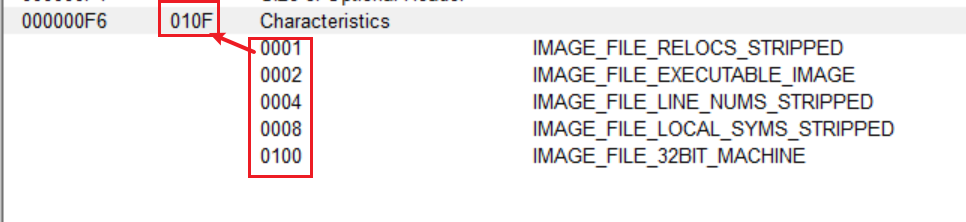
文件头的Characteristics字段用来标识文件的属性,文件是否是可运行的形态,,是否位DLL文件等信息。以bit OR的形式组合起来,就是所有的属性特征值进行OR运算,如图
TimeDateStamp成员的值用来记录文件创建的用时间戳标识的日期,它不影响文件的运行。
NT头:可选头
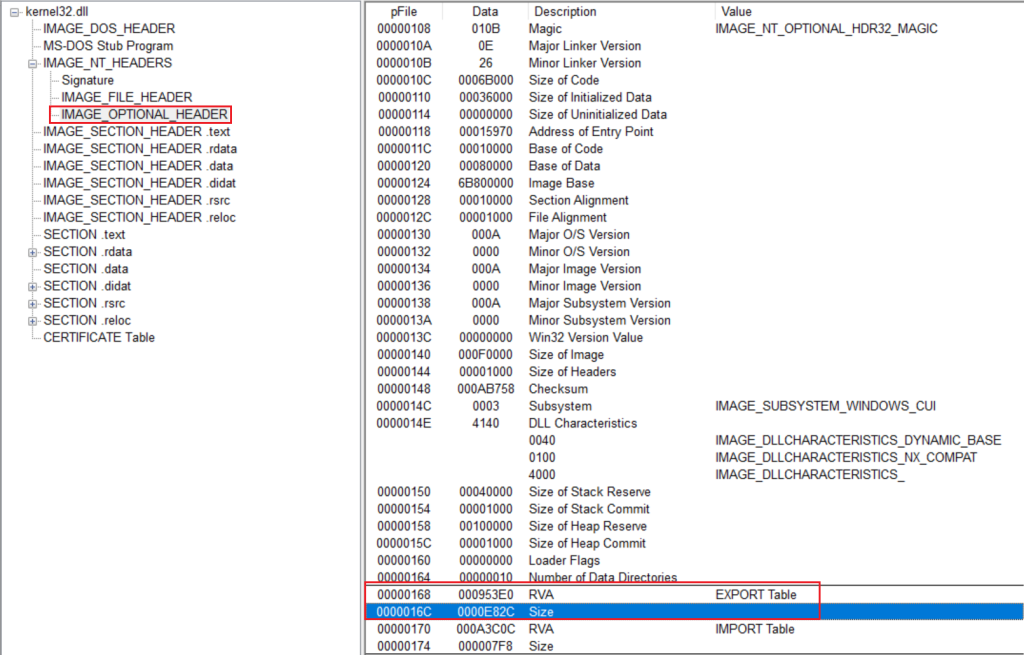
可选头,即IMAGE_OPTIONAL_HEADER32是PE头结构当中最大的。其结构如下
typedef struct _IMAGE_OPTIONAL_HEADER
{
WORD Magic; //* PE标志字:32位(0x10B),64位(0x20B)
BYTE MajorLinkerVersion; // 主链接器版本号
BYTE MinorLinkerVersion; // 副链接器版本号
DWORD SizeOfCode; // 代码所占空间大小(代码节大小)
DWORD SizeOfInitializedData; // 已初始化数据所占空间大小
DWORD SizeOfUninitializedData; // 未初始化数据所占空间大小
DWORD AddressOfEntryPoint; //* 程序执行入口RVA,(w)(Win)mainCRTStartup:即0D首次断下来的自进程地址
DWORD BaseOfCode; // 代码段基址
DWORD BaseOfData; // 数据段基址
DWORD ImageBase; //* 内存加载基址,exe默认0x400000,dll默认0x10000000
DWORD SectionAlignment; //* 节区数据在内存中的对齐值,一定是4的倍数,一般是0x1000(4096=4K)
DWORD FileAlignment; //* 节区数据在文件中的对齐值,一般是0x200(磁盘扇区大小512)
WORD MajorOperatingSystemVersion; // 要求操作系统最低版本号的主版本号
WORD MinorOperatingSystemVersion; // 要求操作系统最低版本号的副版本号
WORD MajorImageVersion; // 可运行于操作系统的主版本号
WORD MinorImageVersion; // 可运行于操作系统的次版本号
WORD MajorSubsystemVersion; // 主子系统版本号:不可修改
WORD MinorSubsystemVersion; // 副子系统版本号
DWORD Win32VersionValue; // 版本号:不被病毒利用的话一般为0,XP中不可修改
DWORD SizeOfImage; //* PE文件在进程内存中的总大小,与SectionAlignment对齐
DWORD SizeOfHeaders; //* PE文件头部在文件中的按照文件对齐后的总大小(所有头 + 节表)
DWORD CheckSum; // 对文件做校验,判断文件是否被修改:3环无用,MapFileAndCheckSum获取
WORD Subsystem; // 子系统,与连接选项/system相关:1=驱动程序,2=图形界面,3=控制台/Dll
WORD DllCharacteristics; // 文件特性
DWORD SizeOfStackReserve; // 初始化时保留的栈大小
DWORD SizeOfStackCommit; // 初始化时实际提交的栈大小
DWORD SizeOfHeapReserve; // 初始化时保留的堆大小
DWORD SizeOfHeapCommit; // 初始化时实际提交的堆大小
DWORD LoaderFlags; // 已废弃,与调试有关,默认为 0
DWORD NumberOfRvaAndSizes; // 下边数据目录的项数,此字段自Windows NT发布以来,一直是16
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];// 数据目录表
} IMAGE_OPTIONAL_HEADER32, * PIMAGE_OPTIONAL_HEADER32;第一个成员Magic,32位系统为IMAGE_OPTIONAL_HEADER32,此时Magic码为10B,64位系统为IMAGE_OPTIONAL_HEADER64,此时Magic码为20B。
6.节区头
节区头定义了各个节区的属性。
创建多个节区可以保证程序的安全性,可以防止不同节区的数据放在一起,写数据导致其他类别数据被覆盖的问题,每个节区有着不同的访问权限和特性

每一个节区都有它自己的结构体IMAGE_SERCTION_HEADER
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];//8字节的块名区块尺寸
union {
DWORD PhysicalAddress;
DWORD VirtualSize; //内存中节区所占大小
} Misc;
DWORD VirtualAddress;//内存中的节区起始地址(RVA)
DWORD SizeOfRawData;//磁盘文件中节区所占大小
DWORD PointerToRawData;//磁盘文件中节区起始位置
DWORD PointerToRelocations;//在 OBJ文件中使用,重定位的偏移
DWORD PointerToLinenumbers;//行号表的偏移(供调试用)
WORD NumberOfRelocations;//在OBJ文件中使用,重定位项数目
WORD NumberOfLinenumbers;//行号表中行号的数目
DWORD Characteristics;//区块的属性(bit OR)
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;Name字段不像C语言成员一样以NULL结束,没有必须ASCLL码的限制。PE规范没有明确节区的Name,所以可以向其中放入任何值,也可以填充NULL值。这里面的意思我理解为可以任意对节区的名字命名,存储数据的节区我们甚至也可以命名为.code,而且在CTF当中,也见过对节区名的改动。
7.IAT
IAT (Import Address Table,导人地址表), EAT(Export Address Table,导出地址表)
IAT保存的内容与Windows操作系统的核心进程、内存、DLL结构等有关。IAT用来记录程序正在使用哪些库中的哪些函数。
IAT是关于DLL的,DLL是啥在这里就不介绍了,加载DLL的方式实际有两种:一种是“显式链接” (Explicit Linking),程序使用DLL时加载,使用完毕后释放内存;另一种是“隐式链接” (Implicit Linking),程序开始时即一同加载DLL,程序终止时再释放占用的内存。IAT提供的机制即与隐式链接有关。
IMAGE_IMPORT_DESCRIPTOR
IMAGE_IMPORT_DESCRIPTOR结构体当中记录着PE文件要导入哪些库文件,其结构如下
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{
union
{
DWORD Characteristics;
DWORD OriginalFirstThunk; // INT(Import Name Table) address 指向IMAGE_IMPORT_BY_NAME的地址(RVA)
};
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name; // 库名称字符串的地址(RVA)
DWORD FirstThunk; // IAT(Import Address Table) IAT的地址(RVA)
} IMAGE_IMPORT_DESCRIPTOR;
typedef struct _IMAGE_IMPORT_BY_NAME
{
WORD Hint;
BYTE Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;执行一个普通程序往往需要导入多个库,导入多少库就有多少个IMAGE_IMPORT_DESCRIPTOR结构体,这些结构体会构成一个数组,结构体最后以NULL结尾,IMAGE_IMPORT_DESCRIPTOR的结构体数组也叫做IMPORT Directory Table,如图
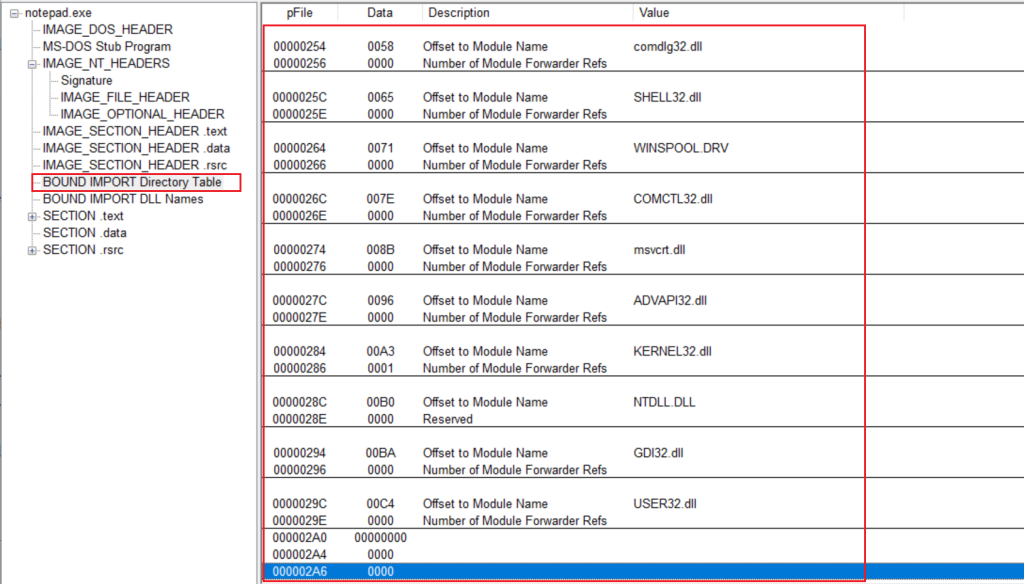
IMAGE_IMPORT_DESCRIPTOR中的重要成员如下
//OriginalFirstThunk INT的地址(RVA)
//INT即Import Name Table
//Name 库名称字符串的地址(RVA)
//FirstThunk IAT的地址(RVA)有如下提示

下面是PE装载器把导入函数输入至IAT的顺序。
- 读取IID的Name的成员,获取库名的字符串 (“kernel32.dll”)
- 装载相应库 -> LoadLibrary(“kernel32.dll”)
- 读取IID的OriginalFirstThunk成员,获取INT地址
- 逐一读取INT中数组的值,获取相应IMAGE_IMPORT_BY_NAME地址(RVA)
- 使用IMAGE_IMPORT_BY_NAME的Hint (ordinal) 或Name项,获取相应函数的起始地址。->GetProcAddress(“GetCurrentThreadId”)
- 读取IID的FirstThunk (IAT) 成员,获取IAT地址
- 将上面获得的函数地址输入相应的IAT数组值
- 重复4~7步骤,直到INT结束(遇到NULL)
接下来使用notepad进行练习
IMAGE_IMPORT_DESCRIPTOR的位置在PE体当中,但查找其位置信息要在PE头当中
IMAGE_OPTIONAL_HEADER32.DataDirectory[1].VirtualAddress的值即是IMAGE_IMPORT_DESCRIPTOR结构体数组的起始位置。
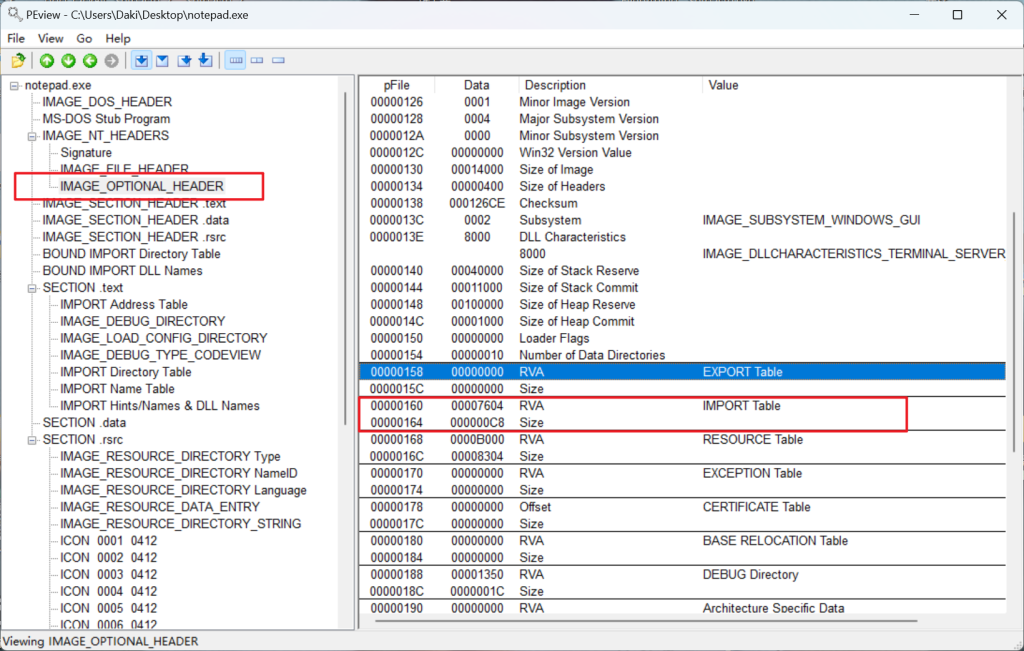
这里的RVA为7604,经计算则RAW为6A04,用到上面那个介绍RVA转换到RAW的图。
如图则为IMAGE_IMPORT_DESCRIPTOR结构体数组,大小为C8,其中开头到第二行的C4 12 00 00为结构体数组的第一个元素。
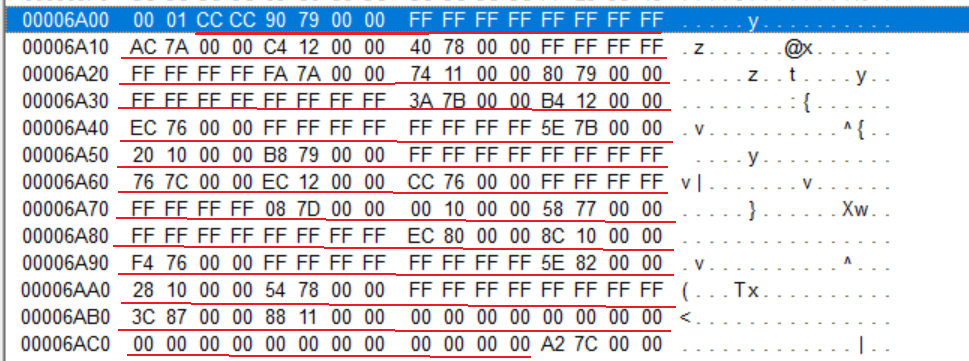
下面来具体看看结构体数组的第一个结构体的各个成员

这里有个Characteristics成员没有,是因为C语言中的union{}语法,似乎只能存在一个成员
1.Name
看文件偏移6EAC (RVA:7AAC->RAW:6EAC) 处

comdlg32.dll,可见Name就是库名称
2.OriginalFirstThunk – INT
INT是一个包含导入函数信息的结构体数组,获得了这些信息,才能在加载到进程内存的库中准确求得相应函数的起始地址,这需要参考后面的EAT讲解。
跟踪OriginalFirstThunk成员来到文件偏移6D90 (RVA:7990->RAW:6D90) 处,即为INT,由地址数组形式组成,每个地址值分别指向IMAGE_IMPORT_BY_NAME结构体,接下来我们跟踪数组的第一个值7A7A,进入该地址,可以看到导入的API函数的名称字符串。
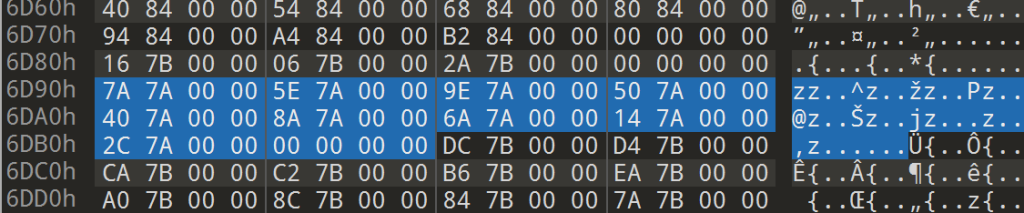
3.IMAGE_IMPORT_BY_NAME
来到文件偏移6E7A (RVA:7A7A->RAW:6E7A) 处

前两个字节值 (000F) 为Ordinal,是库中函数的固有编号,后面为函数名称字符串PageSetupDlgW,字符串末尾同C语言一样,以NULL(‘\0’)结束
所以INT是IMAGE_IMPORT_BY_NAME结构体指针数组,数组的第一个元素指向函数的Ordinal值000f,名称为PageSetupDlgW。
4.FirstThunk – IAT(Import Address Table)
来到文件偏移6C4 (RVA:12C4->RAW:6C4) 处

6C4~6EB区域即为IAT数组区域,对应于comdlg32.dll库,它与INT类似,由结构体指针数组组成,且以NULL结尾
这里的四个字节的值,即为函数的地址值,比如76324906为PageSetupDlgW函数的准确地址值,但是这个值是当时作者使用系统的该函数的地址值,程序在不同系统运行时,PE装载器会使用相应API的起始地址替换该值。
EAT
EAT是一种核心机制,它使得不同的应用程序可以调用库文件中提供的函数。也就是说,只有通过EAT才能准确求得从相应库中导出函数的起始地址。与IAT一样,PE文件内的特定结构体 (IMAGE_EXPORT_DIRECTORY) 保存着导出信息,且PE文件中仅有一个用来说明库EAT的IMAGE_EXPORT_DIRECTORY结构体
可以在PE头当中查找该结构体的位置,和IAT一样,这里是指的在库文件当中查找其结构体。
IMAGE_EXPORT_DIRECTORY的结构体代码如下
typedef struct _IMAGE_EXPORT_DIRECTORY
{
DWORD Characteristics;
DWORD TimeDateStamp; // creation time date stamp (创建时间日期戳)
DWORD MajorVersion;
DWORD MinorVersion;
DWORD Name; // address of library file name (库文件名地址)
DWORD Base; // ordinal base (序数基数)
DWORD NumberOfFunctions; // number of functions
DWORD NumberOfNames; // number of names
DWORD AddressOfFunctions; // address of function start address array
DWORD AddressOfNames; // address of function name string array
DWORD AddressOfOrdinals; // address of ordinal array
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;介绍其中的重要成员
//NumberOfFunctions 实际Export函数的个数
//NumberOfNames Export函数中具名的函数个数
//AddressOfFunctions Export函数地址数组 (数组元素个数=NumberOfFuntions)
//AddressOfNames 函数名称地址数组 (数组元素个数=NumberOfNames)
//AddressOfNameOrdinals Ordinal地址数组 (数组元素个数=NumberOfNames)从库中获取函数地址的API为 GetProcAddress() 函数,该API引用EAT来获取指定API的地址, GetProcAddress() API拥有函数名称下面讲解其如何获取函数地址
从库中获取函数地址的API为 GetProcAddress() 函数,该API引用EAT来获取指定API的地址,下面写下获取函数地址的流程
- 利用 AddressOfNames 成员转到 “函数名称数组”
- “函数名称数组” 中存储着字符串地址。通过比较(strcmp)字符串,查找指定的函数名称(此时数组的索引值称为name_index)
- 利用 AddressOfNameOrdinal 成员,转到 ordinal 数组
- 在 ordinal 数组中通过 name_index 查找相应 ordinal 值
- 利用 AddressOfFunctions 成员转到 “函数地址数组”(EAT)
- 在 “函数地址数组” 中将刚刚求得的 ordinal 用作数组索引,获得指定函数的起始地址
(也就是上面1到5步都是找获得确定索引值,然后从EAT起始地址通过索引值找到正确地址)
提示: 对于没有函数名称的导出函数,可以通过 Ordinal 查找它们的地址。从Ordinal值中减去IMAGE_EXPORT_DIRECTORY.Base成员后得到一个值,使用该值作为“函数地址数组”的索引。
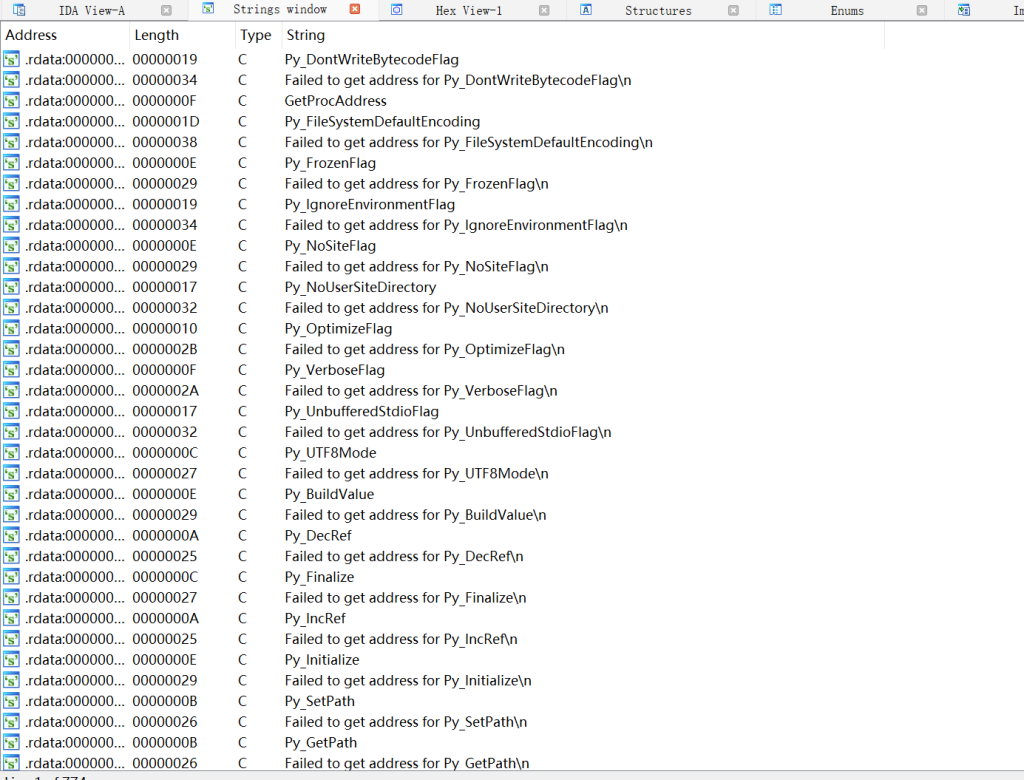
下面使用kernel32.dll进行练习,从其EAT中查找AddAtomW函数,如图
来到文件偏移